- 适用于 JDK 24 的 GraalVM(最新)
- 适用于 JDK 25 的 GraalVM(早期访问)
- 适用于 JDK 21 的 GraalVM
- 适用于 JDK 17 的 GraalVM
- 存档
- 开发构建
沙盒
GraalVM 允许用基于 JVM 的语言编写的主机应用程序通过 Polyglot API 执行用 Javascript 编写的客户代码。通过配置 沙盒策略,可以在主机应用程序和客户代码之间建立安全边界。例如,主机代码可以使用 UNTRUSTED 策略执行不受信任的客户代码。主机代码还可以执行多个相互不信任的客户代码实例,这些实例将相互保护。以这种方式使用时,沙盒支持多租户场景。
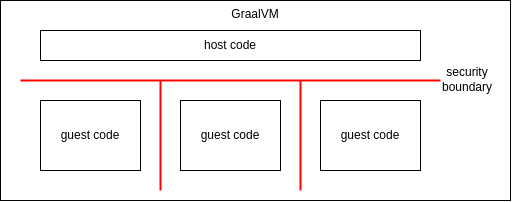
受益于引入安全边界的用例包括:
- 第三方代码的使用,即引入依赖项。第三方代码通常在使用前被信任并扫描漏洞,但对其进行沙盒化是防范供应链攻击的额外预防措施。
- 用户插件。复杂的应用程序可能允许用户安装社区编写的插件。传统上,这些插件被认为是受信任的,并且通常以完全权限运行,但理想情况下,它们不应该干扰应用程序,除非是预期目的。
- 服务器脚本。允许用户使用通用脚本语言表达的自定义逻辑来自定义服务器应用程序,例如,在共享数据源上实现自定义数据处理。
沙盒策略 #
根据用例和相关的可接受安全风险,可以选择 SandboxPolicy,范围从 TRUSTED 到 受信任策略 #
TRUSTED 沙盒策略旨在用于完全受信任的客户代码。这是默认模式。对上下文或引擎配置没有限制。
示例
try (Context context = Context.newBuilder("js")
.sandbox(SandboxPolicy.TRUSTED)
.build();) {
context.eval("js", "print('Hello JavaScript!');");
}
受限策略 #
CONSTRAINED 沙盒策略旨在用于其对主机资源的访问应受管制的受信任应用程序。CONSTRAINED 策略:
- 要求为上下文设置语言。
- 禁止原生访问。
- 禁止进程创建。
- 禁止系统退出,禁止客户代码终止整个 VM(如果语言支持)。
- 要求重定向标准输出和错误流。这是为了缓解外部组件(例如日志处理)可能因客户代码对输出流的意外写入而混淆的风险。
- 禁止主机文件或套接字访问。只允许自定义的多语言文件系统实现。
- 禁止环境访问。
- 限制主机访问
- 禁止主机类加载。
- 默认禁止访问所有公共主机类和方法。
- 禁止访问继承。
- 禁止实现任意主机类和接口。
- 禁止实现
java.lang.FunctionalInterface。 - 禁止可变目标类型的主机对象映射。HostAccess.CONSTRAINED 主机访问策略已预配置,以满足 CONSTRAINED 沙盒策略的要求。
示例
try (Context context = Context.newBuilder("js")
.sandbox(SandboxPolicy.CONSTRAINED)
.out(new ByteArrayOutputStream())
.err(new ByteArrayOutputStream())
.build()) {
context.eval("js", "print('Hello JavaScript!');");
}
隔离策略 #
ISOLATED 沙盒策略在 CONSTRAINED 策略之上构建,旨在用于可能因实现错误或处理不受信任的输入而行为不当的受信任应用程序。顾名思义,ISOLATED 策略在主机和客户代码之间强制执行更深层次的隔离。特别是,使用 ISOLATED 策略运行的客户代码将在其自己的虚拟机(在单独的堆上)中执行。这意味着它们不再与主机应用程序共享运行时元素,例如 JIT 编译器或垃圾收集器,从而使主机 VM 对客户 VM 中的故障更具弹性。
除了 CONSTRAINED 策略的限制外,ISOLATED 策略还:
- 要求启用方法作用域。这避免了主机和客户对象之间的循环依赖。HostAccess.ISOLATED 主机访问策略已预配置,以满足 ISOLATED 沙盒策略的要求。
- 要求设置最大隔离堆大小。这是客户 VM 将使用的堆大小。如果引擎由多个上下文共享,这些上下文的执行将共享隔离堆。
- 要求设置主机调用堆栈余量。这可以防止在向上调用主机时主机堆栈耗尽:如果剩余堆栈大小低于指定值,则将禁止客户进行向上调用。
- 要求设置最大 CPU 时间限制。这限制了工作负载在给定时间范围内执行。
示例
try (Context context = Context.newBuilder("js")
.sandbox(SandboxPolicy.ISOLATED)
.out(new ByteArrayOutputStream())
.err(new ByteArrayOutputStream())
.option("engine.MaxIsolateMemory", "256MB")
.option("sandbox.MaxCPUTime", "2s")
.build()) {
context.eval("js", "print('Hello JavaScript!');");
}
自 Polyglot API 版本 23.1 起,隔离和不受信任的策略还要求在类或模块路径上指定语言的隔离映像。可以使用以下依赖项从 Maven 下载语言的隔离版本:
<dependency>
<groupId>org.graalvm.polyglot</groupId>
<artifactId>js-isolate</artifactId>
<version>${graalvm.polyglot.version}</version>
<type>pom</type>
</dependency>
嵌入语言指南包含有关使用 Polyglot 隔离依赖项的更多详细信息。
不受信任策略 #
UNTRUSTED 沙盒策略在 ISOLATED 策略之上构建,旨在缓解运行实际不受信任代码的风险。GraalVM 在运行不受信任代码时的攻击面包括执行代码的整个客户 VM 以及提供给客户代码的主机入口点。
除了 ISOLATED 策略的限制外,UNTRUSTED 策略还:
- 要求重定向标准输入流。
- 要求设置客户代码的最大内存消耗。这是除了最大隔离堆大小之外的一个限制,由一种机制支持,该机制跟踪客户代码在客户 VM 堆上分配的对象的大小。这个限制可以被认为是“软”内存限制,而隔离堆大小是“硬”限制。
- 要求设置客户代码可以推入堆栈的最大堆栈帧数。这个限制可以防止耗尽堆栈的无界递归。
- 要求设置客户代码的任何抽象语法树 (AST) 的最大深度。与堆栈帧限制一起,这限制了客户代码消耗的堆栈空间。
- 要求设置最大输出和错误流大小。由于输出和错误流必须重定向,接收端在主机侧。限制输出和错误流大小可以防止主机上的可用性问题。
- 要求启用不受信任代码缓解措施。不受信任代码缓解措施解决了 JIT 喷射和推测执行攻击的风险。它们包括常量盲化以及推测执行屏障的全面使用。
- 进一步限制主机访问,以确保没有隐式的主机代码入口点。这意味着客户代码不允许访问主机数组、列表、映射、缓冲区、可迭代对象和迭代器。原因是主机侧可能存在这些 API 的各种实现,导致隐式入口点。此外,通过 HostAccess.Builder#allowImplementationsAnnotatedBy 将客户实现直接映射到主机接口是不允许的。HostAccess.UNTRUSTED 主机访问策略已预配置,以满足 UNTRUSTED 沙盒策略的要求。
示例
try (Context context = Context.newBuilder("js")
.sandbox(SandboxPolicy.UNTRUSTED)
.in(new ByteArrayInputStream("foobar".getBytes()))
.out(new ByteArrayOutputStream())
.err(new ByteArrayOutputStream())
.allowHostAccess(HostAccess.UNTRUSTED)
.option("engine.MaxIsolateMemory", "1024MB")
.option("sandbox.MaxHeapMemory", "128MB")
.option("sandbox.MaxCPUTime","2s")
.option("sandbox.MaxStatements","50000")
.option("sandbox.MaxStackFrames","2")
.option("sandbox.MaxThreads","1")
.option("sandbox.MaxASTDepth","10")
.option("sandbox.MaxOutputStreamSize","32B")
.option("sandbox.MaxErrorStreamSize","0B");
.build()) {
context.eval("js", "print('Hello JavaScript!');");
}
有关如何设置资源限制的更多信息,请参阅相应的指南。
主机访问 #
GraalVM 允许在主机和客户代码之间交换对象,并将主机方法公开给客户代码。当将主机方法公开给特权较低的客户代码时,这些方法成为特权较高主机代码的攻击面。因此,沙盒策略已经在 CONSTRAINED 策略中限制了主机访问,以使主机入口点变得明确。
HostAccess.CONSTRAINED 是 CONSTRAINED 沙盒策略的预定义主机访问策略。要公开主机类方法,必须使用 @HostAccess.Export 注解。此注解不可继承。服务提供者,例如 Polyglot API FileSystem 实现或用于标准输出和错误流重定向的输出流接收器,都暴露给客户代码调用。
客户代码还可以实现用 @Implementable 注解的 Java 接口。使用此类接口的主机代码直接与客户代码交互。
与客户代码交互的主机代码必须以健壮的方式实现:
- 输入验证。所有从客户传递的数据,例如,通过参数传递给公开的方法,都是不受信任的,主机代码应在适用时进行彻底验证。
- 重入性。公开的主机代码应是可重入的,因为客户代码可能随时调用它。请注意,简单地将
synchronized关键字应用于代码块不一定使其可重入。 - 线程安全。公开的主机代码应是线程安全的,因为客户代码可能同时从多个线程调用它们。
- 资源消耗。公开的主机代码应注意其资源消耗。特别是,直接或间接(例如,通过递归)根据不受信任的输入数据分配内存的构造应完全避免或实现限制。
- 特权功能。通过公开提供受限功能的主机方法,可以完全绕过沙盒强制执行的限制。例如,具有 CONSTRAINED 沙盒策略的客户代码无法执行主机文件 IO 操作。然而,向允许写入任意文件的上下文公开主机方法有效地绕过了此限制。
- 侧信道。根据客户语言的不同,客户代码可能可以访问计时信息。例如,在 Javascript 中,
Date()对象提供了细粒度的计时信息。在 UNTRUSTED 沙盒策略中,Javascript 计时器的粒度预配置为一秒,并可以降低到 100 毫秒。然而,主机代码应注意客户代码可能会对其执行进行计时,如果主机代码执行依赖于秘密的处理,则可能会发现秘密信息。
不了解与不受信任客户代码交互的主机代码,在不考虑上述方面的情况下,绝不应直接暴露给客户代码。例如,一个反模式是实现第三方接口并将所有方法调用转发到客户代码。
资源限制 #
ISOLATED 和 UNTRUSTED 沙盒策略要求为上下文设置资源限制。可以为每个上下文提供不同的配置。如果超出限制,代码评估将失败,并且上下文将因 PolyglotException 而取消,该异常的 isResourceExhausted() 返回 true。此时,上下文中不能再执行任何客户代码。
--sandbox.TraceLimits 选项允许您跟踪客户代码并记录最大资源利用率。这可用于估算沙盒的参数。例如,可以通过启用此选项并对服务器进行压力测试,或让服务器在高峰使用期间运行来获取 Web 服务器的沙盒参数。启用此选项后,报告将在工作负载完成后保存到日志文件。用户可以使用语言启动器中的 --log.file=<path> 或使用 java 启动器时的 -Dpolyglot.log.file=<path> 来更改日志文件的位置。报告中的每个资源限制都可以直接传递给沙盒选项以强制执行限制。
例如,如何跟踪 Python 工作负载的限制:
graalpy --log.file=limits.log --sandbox.TraceLimits=true workload.py
limits.log:
Traced Limits:
Maximum Heap Memory: 12MB
CPU Time: 7s
Number of statements executed: 9441565
Maximum active stack frames: 29
Maximum number of threads: 1
Maximum AST Depth: 15
Size written to standard output: 4B
Size written to standard error output: 0B
Recommended Programmatic Limits:
Context.newBuilder()
.option("sandbox.MaxHeapMemory", "2MB")
.option("sandbox.MaxCPUTime","10ms")
.option("sandbox.MaxStatements","1000")
.option("sandbox.MaxStackFrames","64")
.option("sandbox.MaxThreads","1")
.option("sandbox.MaxASTDepth","64")
.option("sandbox.MaxOutputStreamSize","1024KB")
.option("sandbox.MaxErrorStreamSize","1024KB")
.build();
Recommended Command Line Limits:
--sandbox.MaxHeapMemory=12MB --sandbox.MaxCPUTime=7s --sandbox.MaxStatements=9441565 --sandbox.MaxStackFrames=64 --sandbox.MaxThreads=1 --sandbox.MaxASTDepth=64 --sandbox.MaxOutputStreamSize=1024KB --sandbox.MaxErrorStreamSize=1024KB
如果工作负载发生变化或切换到不同的主要 GraalVM 版本,可能需要重新分析。
某些限制可以在执行期间的任何时间点重置。
限制活动 CPU 时间 #
sandbox.MaxCPUTime 选项允许您指定运行客户代码所花费的最大 CPU 时间。CPU 时间的消耗取决于底层硬件。最大CPU 时间指定一个上下文可以活动多长时间,直到它自动取消并关闭。默认情况下,时间限制每 10 毫秒检查一次。这可以使用 sandbox.MaxCPUTimeCheckInterval 选项进行自定义。
一旦触发时间限制,就不能再使用此上下文执行任何客户代码。对于将调用的 polyglot 上下文的任何方法,它将持续抛出 PolyglotException。
上下文使用的 CPU 时间包括回调主机代码所花费的时间。
上下文使用的 CPU 时间通常不包括等待同步或 IO 所花费的时间。所有线程的 CPU 时间将被累加并与 CPU 时间限制进行检查。这意味着,如果两个线程执行相同的上下文,则时间限制将以两倍的速度超过。
时间限制由一个单独的高优先级线程强制执行,该线程会定期被唤醒。不保证上下文将在指定的精度内取消。精度可能会显著偏离,例如,如果主机 VM 导致完全垃圾回收。如果从未超出时间限制,则客户上下文的吞吐量不受影响。如果一个上下文的时间限制被超出,则它可能会暂时降低使用相同显式引擎的其他上下文的吞吐量。
指定时间持续时间的可用单位是 ms(毫秒)、s(秒)、m(分钟)、h(小时)和 d(天)。最大 CPU 时间限制和检查间隔都必须是正数,后跟时间单位。
try (Context context = Context.newBuilder("js")
.option("sandbox.MaxCPUTime", "500ms")
.build();) {
context.eval("js", "while(true);");
assert false;
} catch (PolyglotException e) {
// triggered after 500ms;
// context is closed and can no longer be used
// error message: Maximum CPU time limit of 500ms exceeded.
assert e.isCancelled();
assert e.isResourceExhausted();
}
限制已执行语句的数量 #
指定一个上下文在取消之前可以执行的最大语句数。一旦上下文的语句限制被触发,它就不再可用,并且上下文的每次使用都将抛出 PolyglotException,其中 PolyglotException.isCancelled() 返回 true。语句限制与执行线程的数量无关。
该限制可以设置为负数以禁用它。是否仅将此限制应用于内部源可以通过 sandbox.MaxStatementsIncludeInternal 进行配置。默认情况下,该限制不包括标记为内部的源中的语句。如果使用共享引擎,则引擎的所有上下文都必须使用相同的内部配置。
单个语句的复杂性可能不是恒定时间,具体取决于客户语言。例如,执行 Javascript 内置函数(如 Array.sort)的语句可能只算作一个语句,但其执行时间取决于数组的大小。
try (Context context = Context.newBuilder("js")
.option("sandbox.MaxStatements", "2")
.option("sandbox.MaxStatementsIncludeInternal", "false")
.build();) {
context.eval("js", "purpose = 41");
context.eval("js", "purpose++");
context.eval("js", "purpose++"); // triggers max statements
assert false;
} catch (PolyglotException e) {
// context is closed and can no longer be used
// error message: Maximum statements limit of 2 exceeded.
assert e.isCancelled();
assert e.isResourceExhausted();
}
AST 深度限制 #
对客户语言函数最大表达式深度的限制。只有可检测节点才计入限制。
AST 深度可以估算函数的复杂性及其堆栈帧大小。
限制堆栈帧的数量 #
指定上下文可以推入堆栈的最大帧数。函数进入时增加线程局部堆栈帧计数器,函数返回时减少。
堆栈帧限制本身是防止无限递归的保障。与 AST 深度限制一起,它可以限制总堆栈空间使用。
限制活动线程的数量 #
限制上下文在同一时间点可以使用的线程数。UNTRUSTED 沙盒策略不支持多线程。
堆内存限制 #
sandbox.MaxHeapMemory 选项指定客户代码在其运行期间允许保留的最大堆内存。只有客户代码中的对象才计入限制——回调到主机代码期间分配的内存不计入。这不是一个硬限制,因为此选项的有效性(也)取决于所使用的垃圾收集器。这意味着客户代码可能会超出此限制。
try (Context context = Context.newBuilder("js")
.option("sandbox.MaxHeapMemory", "100MB")
.build()) {
context.eval("js", "var r = {}; var o = r; while(true) { o.o = {}; o = o.o; };");
assert false;
} catch (PolyglotException e) {
// triggered after the retained size is greater than 100MB;
// context is closed and can no longer be used
// error message: Maximum heap memory limit of 104857600 bytes exceeded. Current memory at least...
assert e.isCancelled();
assert e.isResourceExhausted();
}
该限制通过保留大小计算进行检查,该计算根据已分配字节或低内存通知触发。
已分配字节由一个单独的高优先级线程定期检查。每个内存受限上下文(设置了 sandbox.MaxHeapMemory 的上下文)都有一个这样的线程。保留字节计算由另一个高优先级线程完成,该线程根据需要从已分配字节检查线程启动。如果超出堆内存限制,保留字节计算线程也会取消上下文。此外,当调用低内存触发器时,所有内存受限上下文及其分配检查器将一起暂停。所有单独的保留大小计算都将被取消。每个内存受限上下文的堆中保留字节由一个高优先级线程计算。
堆内存限制不会阻止上下文导致 OutOfMemory 错误。快速连续分配大量对象的客户代码的准确性低于很少分配对象的代码。
上下文的保留大小计算可以通过以下专家选项进行自定义:sandbox.AllocatedBytesCheckInterval, sandbox.AllocatedBytesCheckEnabled, sandbox.AllocatedBytesCheckFactor, sandbox.RetainedBytesCheckInterval, sandbox.RetainedBytesCheckFactor, 和 sandbox.UseLowMemoryTrigger。
当保留字节估算值超出指定 sandbox.MaxHeapMemory 的某个因子时,将触发上下文的保留大小计算。该估算值基于上下文活动线程分配的堆内存。更精确地说,如果可用,该估算值是先前的保留字节计算结果,加上自上次计算开始以来分配的字节。默认情况下,sandbox.MaxHeapMemory 的因子为 1.0,可以通过 sandbox.AllocatedBytesCheckFactor 选项进行自定义。该因子必须为正数。例如,让 sandbox.MaxHeapMemory 为 100MB,sandbox.AllocatedBytesCheckFactor 为 0.5。当分配的字节达到 50MB 时,首次触发保留大小计算。如果计算出的保留大小为 25MB,则当额外分配 25MB 时,将触发下一次保留大小计算,以此类推。
默认情况下,已分配字节每 10 毫秒检查一次。这可以通过 sandbox.AllocatedBytesCheckInterval 进行配置。最小可能间隔为 1ms。任何较小的值都被解释为 1ms。
同一上下文的两次保留大小计算的开始之间,默认间隔至少为 10 毫秒。这可以通过 sandbox.RetainedBytesCheckInterval 选项进行配置。该间隔必须为正数。
可以通过 sandbox.AllocatedBytesCheckEnabled 选项禁用上下文的已分配字节检查。默认情况下,它是启用的(“true”)。如果禁用(“false”),则上下文的保留大小检查只能由低内存触发器触发。
当整个主机 VM 的堆中分配的总字节数超过 VM 总堆内存的某个因子时,将调用低内存通知并启动以下过程。所有设置了 sandbox.MaxHeapMemory 选项的执行上下文都将暂停。只有当计算出每个内存受限上下文的堆中保留字节,并且超出其限制的上下文被取消时,执行才会恢复。默认因子为 0.7。这可以通过 sandbox.RetainedBytesCheckFactor 选项进行配置。该因子必须介于 0.0 和 1.0 之间。所有使用 sandbox.MaxHeapMemory 选项的上下文必须使用相同的 sandbox.RetainedBytesCheckFactor 值。
当任何堆内存池的使用阈值或收集使用阈值已设置时,默认情况下无法使用低内存触发器,因为无法实现 sandbox.RetainedBytesCheckFactor 指定的限制。但是,当 sandbox.ReuseLowMemoryTriggerThreshold 设置为 true 且堆内存池的使用阈值或收集使用阈值已设置时,该内存池的 sandbox.RetainedBytesCheckFactor 值将被忽略,而使用已设置的任何限制。这样,低内存触发器可以与也设置堆内存池使用阈值或收集使用阈值的库一起使用。
可以通过 sandbox.UseLowMemoryTrigger 选项禁用上述低内存触发器。默认情况下,它是启用的(“true”)。如果禁用(“false”),则执行上下文的保留大小检查只能由已分配字节检查器触发。所有使用 sandbox.MaxHeapMemory 选项的上下文必须使用相同的 sandbox.UseLowMemoryTrigger 值。
sandbox.UseLowMemoryTrigger 选项不支持 ISOLATED 和 UNTRUSTED 沙盒策略,因为对于这些策略,polyglot 引擎在 native-image 隔离区中运行。在 native-image 主机上也不支持,无论策略如何。在不支持此选项的地方,它默认为禁用(false)。
限制写入标准输出和错误流的数据量 #
限制客户代码在运行时写入标准输出或标准错误输出的数据大小。限制输出大小可以作为防止拒绝服务攻击(通过淹没输出)的保护。
try (Context context = Context.newBuilder("js")
.option("sandbox.MaxOutputStreamSize", "100KB")
.build()) {
context.eval("js", "while(true) { console.log('Log message') };");
assert false;
} catch (PolyglotException e) {
// triggered after writing more than 100KB to stdout
// context is closed and can no longer be used
// error message: Maximum output stream size of 102400 exceeded. Bytes written 102408.
assert e.isCancelled();
assert e.isResourceExhausted();
}
try (Context context = Context.newBuilder("js")
.option("sandbox.MaxErrorStreamSize", "100KB")
.build()) {
context.eval("js", "while(true) { console.error('Error message') };");
assert false;
} catch (PolyglotException e) {
// triggered after writing more than 100KB to stderr
// context is closed and can no longer be used
// error message: Maximum error stream size of 102400 exceeded. Bytes written 102410.
assert e.isCancelled();
assert e.isResourceExhausted();
}
重置资源限制 #
可以使用 Context.resetLimits 方法随时重置限制。如果应将已知和受信任的初始化脚本排除在限制之外,这会很有用。只能重置语句、CPU 时间和输出/错误流限制。
try (Context context = Context.newBuilder("js")
.option("sandbox.MaxCPUTime", "500ms")
.build();) {
context.eval("js", /*... initialization script ...*/);
context.resetLimits();
context.eval("js", /*... user script ...*/);
assert false;
} catch (PolyglotException e) {
assert e.isCancelled();
assert e.isResourceExhausted();
}
运行时防御 #
ISOLATED 和 UNTRUSTED 沙盒策略通过 engine.SpawnIsolate 选项强制执行的主要防御是,Polyglot 引擎在专用的 native-image 隔离区中运行,将客户代码的执行移动到独立于主机应用程序的 VM 级故障域,拥有自己的堆、垃圾收集器和 JIT 编译器。
除了通过客户堆大小为客户代码的内存消耗设置硬限制外,它还允许将运行时防御仅集中在客户代码上,而不会导致主机代码的性能下降。运行时防御通过 engine.UntrustedCodeMitigation 选项启用。
常量盲化 #
JIT 编译器允许用户提供源代码,并且在源代码有效的情况下,将其编译为机器代码。从攻击者的角度来看,JIT 编译器将攻击者控制的输入编译为可执行内存中可预测的字节。在称为 JIT 喷射的攻击中,攻击者通过向 JIT 编译器提供恶意输入程序来利用可预测的编译,从而迫使其发出包含面向返回编程 (ROP) 小工具的代码。
输入程序中的常量是这种攻击特别有吸引力的目标,因为 JIT 编译器通常将它们原封不动地包含在机器代码中。常量盲化旨在通过在编译过程中引入随机性来使攻击者的预测无效。具体来说,常量盲化在编译时使用随机密钥加密常量,并在运行时每次出现时解密它们。只有常量的加密版本才会原封不动地出现在机器代码中。在不知道随机密钥的情况下,攻击者无法预测加密的常量值,因此无法再预测可执行内存中产生的字节。
GraalVM 盲化了运行时编译的客户代码中代码页内所有立即值和嵌入数据,大小低至四个字节。
随机化函数入口点 #
可预测的代码布局使得攻击者更容易找到已引入的小工具,例如通过前面提到的 JIT 喷射攻击。虽然运行时编译的方法已经放置在受操作系统地址空间布局随机化 (ASLR) 影响的内存中,但 GraalVM 还在函数起始偏移量处填充了随机数量的陷阱指令。
推测执行攻击缓解措施 #
Spectre 等推测执行攻击利用了 CPU 可能基于分支预测信息瞬态执行指令的事实。如果预测错误,这些指令的结果将被丢弃。然而,执行可能已在 CPU 的微体系结构状态中引起了副作用。例如,数据可能在瞬态执行期间被拉入缓存——这是一个可以通过计时数据访问来读取的侧信道。
GraalVM 通过在运行时编译的客户代码中插入推测执行屏障指令来防止 Spectre 攻击,以防止攻击者制造推测执行小工具。在与 Java 内存安全相关的条件分支的每个目标处都放置了一个推测执行屏障,以阻止推测执行。
共享执行引擎 #
不同信任域的客户代码必须在 polyglot 引擎级别进行分离,即只有相同信任域的客户代码才能共享一个引擎。当多个上下文共享一个引擎时,它们都必须具有相同的沙盒策略(引擎的沙盒策略)。应用程序开发人员出于性能原因可能会选择在执行上下文之间共享执行引擎。虽然上下文保存已执行代码的状态,但引擎保存代码本身。在多个上下文之间共享执行引擎需要显式设置,并且可以在多个上下文执行相同代码的场景中提高性能。在共享执行引擎以执行公共代码的上下文也执行敏感(私有)代码的场景中,相应的源对象可以通过以下方式选择不共享代码:
Source.newBuilder(…).cached(false).build()
兼容性和限制 #
GraalVM Community Edition 中不提供沙盒功能。
根据沙盒策略,只有一部分 Truffle 语言、工具和选项可用。特别是,沙盒目前仅支持运行时的 ECMAScript 默认版本(ECMAScript 2022)。GraalVM 的 Node.js 中也不支持沙盒。
沙盒与通过(例如)更改 VM 行为的系统属性对 VM 设置进行的修改不兼容。
沙盒策略可能会在 GraalVM 的主要版本之间发生不兼容的更改,以保持默认安全态势。
沙盒无法防御其操作环境中的漏洞,例如操作系统或底层硬件中的漏洞。我们建议采用适当的外部隔离原语来防御相应的风险。
与 Java 安全管理器的区别 #
Java Security Manager 在 Java 17 中已通过 JEP-411 弃用。安全管理器的目的如下:“它允许应用程序在执行可能不安全或敏感的操作之前,确定该操作是什么,以及是否在允许执行该操作的安全上下文中尝试该操作。”
GraalVM 沙盒的目标是允许以安全方式执行不受信任的客户代码,这意味着不受信任的客户代码不应能够损害主机代码及其环境的机密性、完整性或可用性。
GraalVM 沙盒在以下方面与安全管理器不同:
- 安全边界:Java 安全管理器具有灵活的安全边界,这取决于方法的实际调用上下文。这使得“划定界限”变得复杂且容易出错。安全关键代码块首先需要检查当前调用堆栈,以确定堆栈上的所有帧是否都有权调用该代码。在 GraalVM 沙盒中,存在一个直接、清晰的安全边界:主机和客户代码之间的边界,客户代码在 Truffle 框架之上运行,类似于典型的计算机体系结构如何区分用户模式和(特权)内核模式。
- 隔离:使用 Java 安全管理器,特权代码与不受信任代码在语言和运行时方面几乎“平等”。
- 共享语言:使用 Java 安全管理器,不受信任的代码与特权代码使用相同的语言编写,其优点是两者之间的互操作性直接。相比之下,GraalVM 沙盒中的客户应用程序(使用 Truffle 语言编写)需要跨越显式边界才能访问用 Java 编写的主机代码。
- 共享运行时:使用 Java 安全管理器时,不受信任的代码与受信任的代码在同一个 JVM 环境中执行,共享 JDK 类和运行时服务,如垃圾收集器或编译器。在 GraalVM 沙盒中,不受信任的代码在专用 VM 实例(GraalVM 隔离区)中运行,从设计上就将主机和客户的服务和 JDK 类分离。
- 资源限制:Java 安全管理器无法限制计算资源(如 CPU 时间或内存)的使用,允许不受信任的代码对 JVM 进行 DoS 攻击。GraalVM 沙盒提供控制,可对客户代码可能消耗的多种计算资源(CPU 时间、内存、线程、进程)设置限制,以解决可用性问题。
- 配置:构建 Java 安全管理器策略通常是一项复杂且容易出错的任务,需要一个主题专家精确了解程序的哪些部分需要何种级别的访问。配置 GraalVM 沙盒提供了专注于常见沙盒用例和威胁模型的安全配置文件。
报告漏洞 #
如果您认为您发现了安全漏洞,请通过 secalert_us@oracle.com 提交报告,最好附上概念验证。有关更多信息,包括我们的安全电子邮件公共加密密钥,请参阅报告漏洞。我们请求您不要直接联系项目贡献者或通过其他渠道报告。